This is Hype Data Magic (actually was planned as Hype Data Fill 2) but since I started working on it again duo to client tasks and it just feels like Magic using it… I renamed it. It helps you connect data sources to Hype projects and adds a live preview. I moved the stable code to GitHub but if you want to see a development version (including some fancy stuff like indexes and fetchData) then visit the version that resides on Gumroad. I can't make any promises on how or if these feature will make it into the stable release but your welcome to try and use them.
I decided to release the core version for free so donations (look at my profile) or GitHub sponsoring is very welcome! Specially if you use it commercially and want to return the favor.
Check out the trailer:
Examples:
GitHub:
The official place to download and use this extension from is now GitHub:
I just realized I forgot to expose the refresh handler to the external API. Just add refresh: refresh, to it and call it with the document.documentElement when needed. If you would do that you can even load external data with the live preview if you trigger a refresh after loading is complete with HypeDataMagic.refresh(document.documentElement). In the next update I will add this. Also, the data magic keys are reactive. So, resetting them with a new value refreshes the sub tree and the node with the new values even in the published version. Like the data-magic-branch. So, sliders, here we come.
Update: This makes me think that I will implement full loading capability into the extension taking the need out of figuring out how to connect to external data providers.
Data types are more to be thought of like an decorator pattern. They are applied and receive the endpoint of data assignment. Hence, you can use them to animate a chart or assign data according to your needs (or load a video etc.) but they need an initial dataload to be triggered in the first place. The types will probably be chainable using the pipe symbol to further add to the decorator aspect. If the data also becomes chainable (not sure about that yet) the data would have to be made immutable (deep copy) before each refresh cycle to avoid weird behaviors. Still, not implemented.
One open question: should data types be called data types or data handler. Internally I call them handler and that would be more in the spirit of chainable entities. Types feel more like an 1:1 assignment.
Things that need to be done in the next drop is to debounce mutations as Hype has a very generous and frequent update policy on them but Hype Data Magic uses them as triggers and hence the bare minimum would be more desirable.
The final thing will be the mentioned immutable aspect of data on each update. Meaning that we always fetch a fresh deep copy before passing it to the handlers. Changing data would then be a deliberate act through setData or an additional interface.
For most cases, one wants to use the handler at the HypeScenePrepareForDisplay level. In some cases involving the full Hype API (like triggering animations) one would want the handler to fire using HypeSceneLoad. So, at least two triggers will be needed. Either with the one handler and the event.type or two handlers for each circumstance. I'll investigate.
Update: So, I am in the process of refactoring the code a bit. The main difference being that the mutation-based updates become optional for the exported version. This removes the asynchronous nature and allows me to fire them much more precise. The handlers will now be fired twice but there will be a way to distinguish between scene prepare and load events.
Update2: If you are wondering why I am observing contenteditable in the IDE version. I discovered last fall that you can inject HTML and a double click makes the new content permanent in the current document. I even coded an extension called HypeClickEmbed and another HypeTemplateVars. I never released them as this would depend too much on an unsupported hack/quirk to be used in production even though it offered some neat possibilities. In this case I am actively avoiding this behavior. Meaning, that preview text becomes part of the save file by deleting any content when you double-click a linked rectangle.
Yes, if your interested I can DM you that code but no warranty.
Concerning the extension Hype Data Magic... I fixed most issues and will be releasing the new version ASAP (probably today). I’ll post a ping here and all people that downloaded it on Gumroad will also be notified.
↑ look at project 1.1 Uncoupled refreshes from mutations 1.2 Refactored data handler and IDE preview
I was hard at work updating Hype Data Magic to become more stable. I still consider it "unfinished" but it is slowly getting there. That said, please play around with the update and send me feedback on the forum if you feel like it.
I was still contemplating if I integrate a built-in data loader for external files. Also, I want to add more examples in the near future like a slider, chart or the mentioned example for consuming external JSON with a live preview.
↑ look at project 1.3 added data-magic support for innerHTML and lots of preview fixes
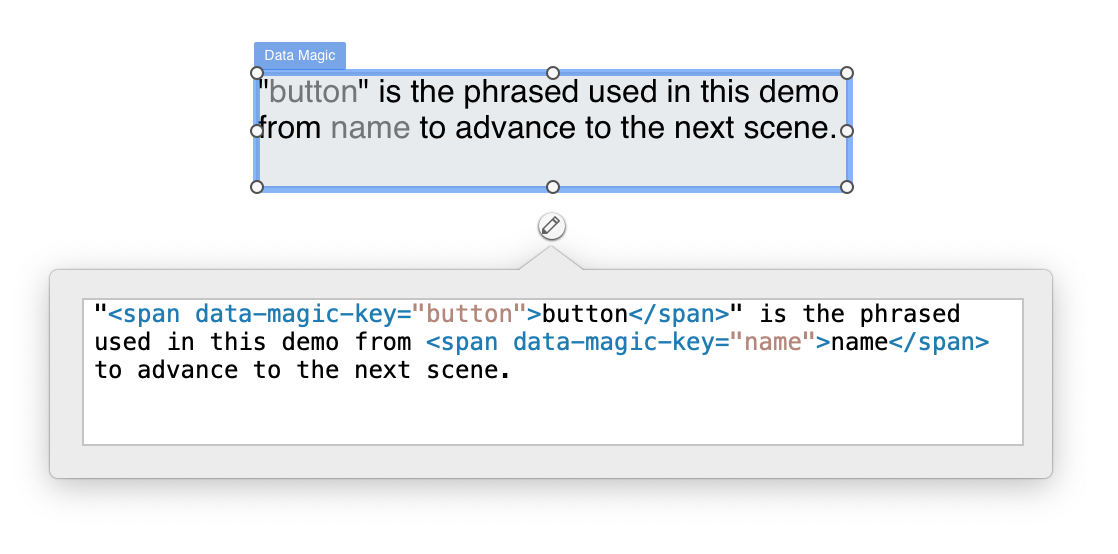
This release concerns mainly the broken live preview and adds a new option to add data-magic-keys into innerHTML instead of in the attribute panel.
Hint: to check if the export contains any static text portions (user imputed and not dynamic) you can always just make a regular test export and enable the inclusion of text in the document for search engines. Then inspect the file to see what text is actually found by Hype in the document. You will see that most of the text in the current test files is really not in the Hype file and actually only a preview directly from you data source. When using the new innerHTML feature only a placeholder is kept for readability. Open for suggestions on the later.
There was also some code refactoring done and some custom behavior commands have been added for your convenience. Happy exploring and do let me know what you think.
I have been busy but this project hasn't been forgotten. I was already exploring some advanced use-cases (indexes and fetchData) in the file found on Gumroad but after returning to the project today I strip all the fancy stuff and released a stable core version ready for production to GitHub. The version number of the GitHub core release now reset to v1.0 to reflect the standalone release. The core release, includes a CDN options, a doxdox documentation and a getting started guide in the GitHub README:
This example is with a simple fetch that loads from resources without any preloader or error handling (easy to add, though). Nothing fancy, but it should demonstrate the case. The code snippet used is:
// element - DOMHTMLElement that triggered this function being called
// event - event that triggered this function being called
function fetch(hypeDocument, element, event) {
// load data using fetch
fetch('${resourcesFolderName}/test.json')
.then(response => response.json())
.then(data => {
HypeDataMagic.setData(data);
});
}
PS: You can also directly include data (head) or use JSONP to avoid any Cross-Origin-Policies.

")